Bayesian Network Representation of Joint Normal Distributions - Cascading Regressions Model
This post is the first of a series discussing the Bayesian Network representation of multivariate normal distributions. A joint normal distribution being fully specified by its mean vector and its covariance matrix is not simple to interact with as its Bayesian network equivalent. Representing a joint normal distribution as a Bayesian network enables visualizing and interacting with the distribution through the lens of probabilistic graphical models with TKRISK®.
We demonstrate in this post a simple yet powerful approach using a cascading regressions approach.
A normal distribution is fully specified using two parameters: its mean and its variance . Likewise, a -dimensional multivariate normal distribution is fully specified by its mean vector and covariance matrix .
The latter can also be represented as a Bayesian Network, more specifically as a Gaussian Bayesian network [KF09] [CBLV20].
In what follows we will be working with a vector of random variables following a multivariate normal distribution .
By definition and .
Through basic matrix operations we will show how can be represented through a cascading regression model which is a particular case of a linear Gaussian Structural Equation Model (SEM) [DFS11][PK19], the latter having a direct Gaussian Bayesian Network equivalent.
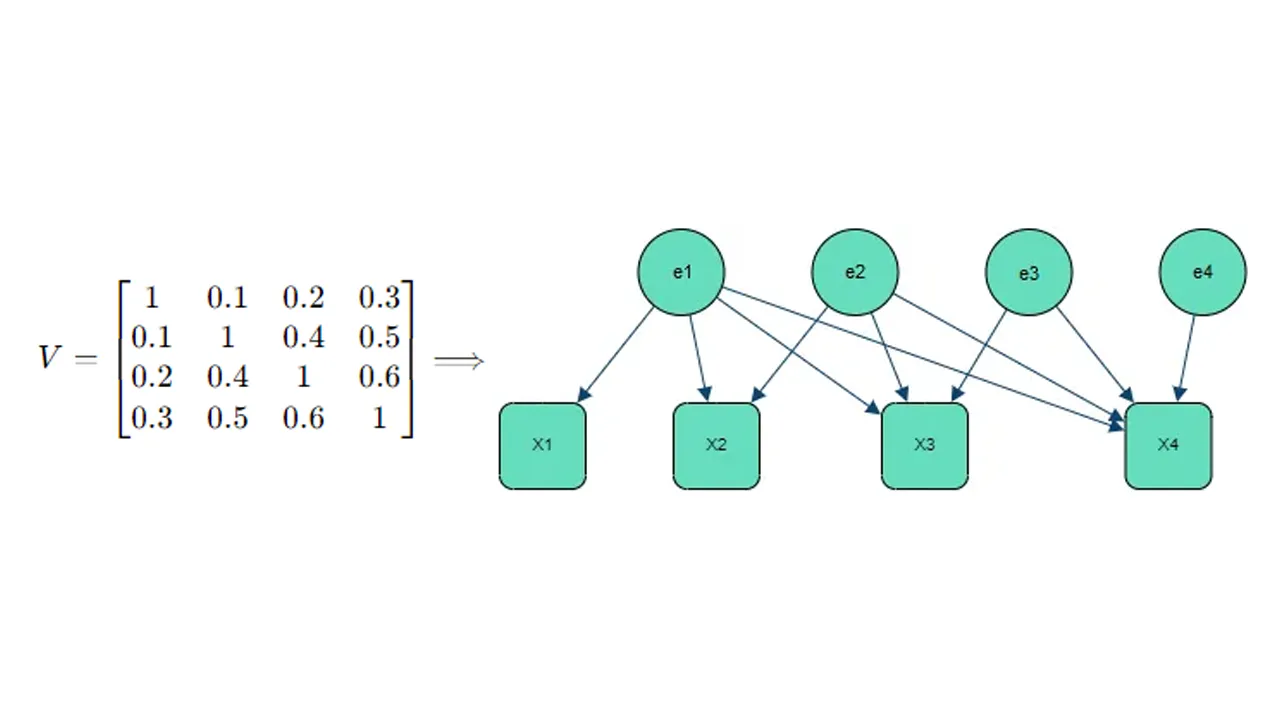
Applying LDL decomposition on yields with being unit lower triangular and diagonal.
Therefore: with .
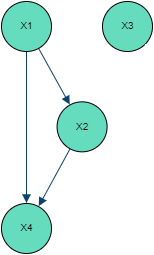
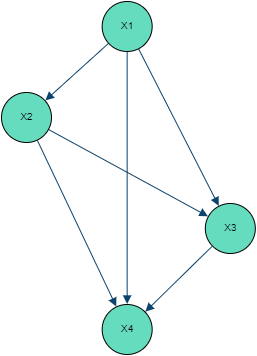
Introducing with being the n-dimensional identity matrix, we obtain the structural model:The above specifies a Gaussian Bayesian Network which can be expressed explicitly for each variable:with:
The terms of matrix B can be interpreted as the linear regression coefficients of each variable over its parents .
It is important to note that a different order in the variables will lead to a different Bayesian Network structure, representing however the exact same joint distribution.
The above approach is simple, computationally efficient and allows Bayesian Networks generation straight from any dataset for which variables are assumed normally distributed. Working with LDL decomposition and requiring only unit lower triangular matrix inversion means the algorithm is flexible to handle any case of covariance matrix (even non definite) and thus any multivariate normal distribution.
It is common to work on standardized normal distributions, i.e. with zero mean and unit variance:
In this case covariance and correlation matrices are one and the same. This is a convenient setup which does not imply loss of generality as non-normalized marginals can be recovered by shifting and scaling the normalized ones. Working on normalized space allows for direct comparison of dependencies between variables as these are independent of their actual magnitude.
For a self-contained graph representation, contrary to the above generic approach, the Gaussian Bayesian Network is insufficient and would require additional deterministic nodes to apply shifting and scaling (shifting and scaling directly a node on the Bayesian Network would propagate on its children and thus alter the joint distribution).
For sake of simplicity we will present examples on standardized normal distributions only.
To visualize and interpret the above approach, we will take basic examples of 4 dimensional multivariate normal distributions.
Independent Independent variables naturally translate to no connections between nodes, with the correlation matrix being the identity matrix.